1. Text Classification?
Teks kategorisasi atau klasifikasi teks adalah tugas menetapkan kategori standar untuk dokumen teks bebas. Hal ini dapat memberikan pandangan konseptual koleksi dokumen dan memiliki aplikasi penting dalam dunia nyata. Sebagai contoh, berita biasanya diselenggarakan oleh kategori subjek (topik) atau kode geografis; makalah akademis sering diklasifikasikan berdasarkan domain teknis dan sub-domain; laporan pasien dalam organisasi kesehatan sering diindeks dari beberapa aspek, menggunakan taksonomi kategori penyakit, jenis prosedur bedah, kode penggantian asuransi dan sebagainya. Aplikasi lain yang luas dari teks kategorisasi adalah spam filtering, di mana pesan email diklasifikasikan ke dalam dua kategori spam dan non-spam, masing-masing.
2. Information Retrieval?
Sistem Temu-Balik Informasi (Information Retrieval) digunakan untuk menemukan kembali informasi-informasi yang relevan terhadap kebutuhan pengguna dari suatu kumpulan informasi secara otomatis. Salah satu aplikasi umum dari sistem temu kembali informasi adalah search-engine atau mesin pencarian yang terdapat pada jaringan internet. Pengguna dapat mencari halaman-halaman Web yang dibutuhkannya melalui mesin tersebut.
Ukuran efektifitas pencarian ditentukan oleh precision dan recall. Precision adalah rasio jumlah dokumen relevan yang ditemukan dengan total jumlah dokumen yang ditemukan oleh search-engine. Precision mengindikasikan kualitas himpunan jawaban, tetapi tidak memandang total jumlah dokumen yang relevan dalam kumpulan dokumen.
![]()
Recall adalah rasio jumlah dokumen relevan yang ditemukan kembali dengan total jumlah dokumen dalam kumpulan dokumen yang dianggap relevan.
![]()
Dalam Information Retrieval, mendapatkan dokumen yang relevan tidaklah cukup. Tujuan yang harus dipenuhi adalah bagaimana mendapatkan doukmen relevan dan tidak mendapatkan dokumen yang tidak relevan. Tujuan lainnya adalah bagaimana menyusun dokumen yang telah didapatkan tersebut ditampilkan terurut dari dokumen yang memiliki tingkat relevansi lebih tingi ke tingkat relevansi rendah. Penyusunan dokumen terurut tersebut disebut sebagai perangkingan dokumen. Model Ruang Vektor dan Model Probabilistik adalah 2 model pendekatan untuk melakukan hal tersebut.
Model ruang vektor dan model probabilistik adalah model yang menggunakan pembobotan kata dan perangkingan dokumen. Hasil retrieval yang didapat dari model-model ini adalah dokumen terangking yang dianggap paling relevan terhadap query.
Dalam model ruang vektor, dokumen dan query direpresentasikan sebagai vektor dalam dalam ruang vektor yang disusun dalam indeks term, kemudian dimodelkan dengan persamaan geometri. Sedangkan model probabilistik membuat asumsi-asumsi distribusi term dalam dokumen relevan dan tidak relevan dalam orde estimasi kemungkinan relevansi suatu dokumen terhadap suatu query.
3.HITS Algorithm?
Hyperlink-Induced Topic Search (HITS, juga dikenal sebagai hub dan otoritas) adalah algoritma analisis link yang tarif halaman Web, yang dikembangkan oleh Jon Kleinberg. Itu adalah pendahulu untuk PageRank. Ide di balik Hub dan Otoritas berasal dari wawasan tertentu ke dalam penciptaan halaman web ketika Internet awalnya membentuk; yaitu, halaman web tertentu, yang dikenal sebagai hub, menjabat sebagai direktori besar yang tidak benar-benar berwibawa dalam informasi yang diadakan, tetapi digunakan sebagai kompilasi dari katalog yang luas dari informasi yang menyebabkan pengguna langsung ke halaman otoritatif lainnya. Dengan kata lain, sebuah hub baik mewakili halaman yang menunjuk ke halaman lain, dan otoritas yang baik mewakili halaman yang dihubungkan oleh banyak hub berbeda.
4.Prolog?
Prolog adalah bahasa pemrograman logika atau di sebut juga sebagai bahasa non-procedural. Namanya diambil dari bahasa Perancis programmation en logique (pemrograman logika). Bahasa ini diciptakan oleh Alain Colmerauer dan Robert Kowalski sekitar tahun 1972 dalam upaya untuk menciptakan suatu bahasa pemrograman yang memungkinkan pernyataan logika alih-alih rangkaian perintah untuk dijalankan komputer.
Berbeda dengan bahasa pemrograman yang lain, yang menggunakan algoritma konvensionl sebagai teknik pencariannya seperti pada Delphi, Pascal, BASIC, COBOL dan bahasa pemrograman yang sejenisnya, maka prolog menggunakan teknik pencarian yang di sebut heuristik (heutistic) dengan menggunakan pohon logika.

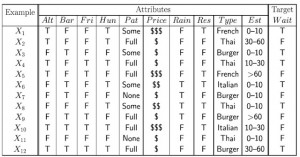 Ada 10 variabel yang digunakan untuk dasar mengambil keputusan. Kelas keputusan ada dua yakni Menunggu/Tidak di sebuah restoran
Ada 10 variabel yang digunakan untuk dasar mengambil keputusan. Kelas keputusan ada dua yakni Menunggu/Tidak di sebuah restoran
Recent Comments